“Did You Miss My Comment or What?”
Understanding Toxicity in Open Source Discussions by Courtney Miller, Sophie Cohen, Daniel Klug, Bogdan Vasilescu, Christian Kästner
I came across this paper a little while ago after having a frustrating discussion on the FOSS United telegram. I am also a part of discussion channels of a few open source projects where I regularly notice a lot of not-polite back and forth among maintainers, users and contributors, which from my experience is unique only to OSS forums.
In this paper the authors try to understand online toxicity in open source communities. The kinds, reasons and effects of toxicity across the internet are well documented, but toxicity specifically within OSS communities is not very well understood.
To this end, we curate a sample of 100 toxic GitHub issue discussions combining multiple search and sampling strategies. We then qualitatively analyze the sample to gain an understanding of the characteristics of open-source toxicity. We find that the pervasive forms of toxicity in open source differ from those observed on other platforms like Reddit or Wikipedia.
From an interview -
They used a toxicity and politeness detector developed for another platform to scan nearly 28 million posts on GitHub made between March and May 2020. The team also searched these posts for “code of conduct” — a phrase often invoked when reacting to toxic content — and looked for locked or deleted issues, which can also be a sign of toxicity.
In our sample, some of the most prevalent forms of toxicity are entitled, demanding, and arrogant comments from project users as well as insults arising from technical disagreements. In addition, not all toxicity was written by people external to the projects; project members were also common authors of toxicity.
Open Source and Toxicity
What is toxicity in the context of online discussions?
Toxicity, defined here as “rude,disrespectful, or unreasonable language that is likely to make some-one leave a discussion” is a huge problem online
Open source communities are not immune to toxicity. While the term “toxicity” as defined above has only recently started being used in the open-source literature, the presence of behaviors “likely to make someone leave” have long been documented by researchers and practitioners in this space. For example, the Linux Kernel Mailing List is notorious for having discussions with a tone that “tends to discourage people from joining the community”
Linus Torvalds acknowledges that he has at times been “overly impolite” and that is “a personal failing.”
Toxicity is also a major threat to diversity and inclusion: prior work has found that it can especially impact members of certain identity groups, particularly women , who are already severely underrepresented.
I remember wanting to contribute to open source a little more than a year back and the tone of the day to day discussions would be a major factor for me to choose which project I would be like to be involved with.
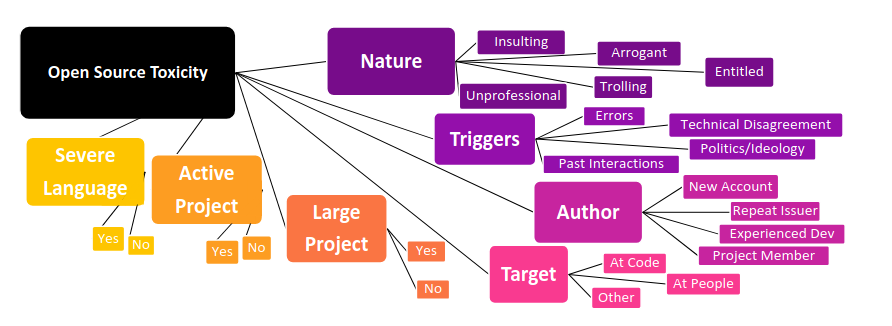
Identified characteristics of open source toxicity
Unlike some other platforms where the most frequent types of toxicity are hate speech or harassment, we find entitlement, insults, and arrogance are among
the most common types of toxicity in open source. We also learned that many of the ways projects address toxicity are closely connected to the GitHub interface itself and open source culture more broadly, such as locking issues as too heated or invoking a project’s code of conduct.
I tried finding if there are any blogs from github on the measures they take to handle toxicity but couldn’t find anything
Edit: GitHub Community Guidelines - GitHub Docs
Another ex-open source community leader, when explaining why they quit, described how “I had been told that I needed a ‘tough skin’ to work in the community, and I needed to ‘not take it personally’ when developers were abrasive during code review”.
Toxicity in open source is often written off as a naturally occurring if not necessary facet of open source culture. The aforementioned community leader describes how “When I complained about the toxic environment, I was told it was ‘tradition’ to be blunt and rude in order to have a truly open dialogue.”
Four high ranking Perl community members stepped down due to community-
related issues. One of them, when elected as community leader in April 2016, set the goal to make the mailing list “a place on which we can have technical conversations without worrying about abusive language or behavior” however, in April 2021, he stepped down explaining how the “chain of continuous bullying and hostility I’ve been receiving” has caused him “significant emotional distress”.
(Types of) Toxicity observed on Github
Insults
Over half of our sample contained insults (55 cases), i.e., disrespectful or scornful expressions, often using curse words or intentionally offensive language. Toxic insulting comments tend to be targeted at people rather than at the code itself.
This is interesting because I’ve heard a lot of seasoned open-sourcerers say to new contributors that they should never take criticism personally and it’s always about the code not the person. The contributor convenant which is one of the most widely adopted COCs explicitly states that criticism should be constructive.
For example, a user of a GUI crypto wallet with a built-in crypto miner noticed the presence of the miner and interpreted it as malware (a misunderstanding, the presence, deactivated by default,was mentioned as an intentional feature in the readme). The user threw explicit curse words at the maintainers of the project and accused them of being “criminal crooks” for trying to “infect other computers with malware”
A project member was unhappy with the colors of a project, reporting “colors are horrible for […], just look at this s**t” . Even after a contributor provided a link to the documentation, the user remained unsatisfied and unapologetic.
Entitled
Entitled comments make demands of people or projects as if the author had an
expectation due to a contractual relationship or payment.
A user, upon being told that their suggestion was based on a misunderstanding of the project, began aggressively criticizing the contributor for how they addressed the issue, saying “Like just add the flavor text or show me how to or something. Don’t just fu**ing close people’s tickets they would like some help on”
Arrogant
We consider comments as arrogant when the author imposes their view on others from a position of perceived authority or superiority (earned or not) and demands that others act as recommended
One of the users in the discussion was unfamiliar with some of the legislation being discussed and asked for more information, a second user responded saying “Never hear about [standard]? A baseline for developers. Use Google.”
Trolling
For example, a user was generally unhappy with a project and wrote “Worst. App. Ever. Please make it not the worst app ever. Thanks” (I2), followed by a pull request that deleted all the code in the repo; after the main-tainer closed the issue, the user responded “Merge my PR damnit” and nothing else happened.
Unprofessional
Comments that are not overly toxic but nonetheless create an unwelcoming environment.
Examples include self directed pejorative terms (e.g., “It seems like I have been acting like a re**rd. Sorry. […]” ), self-deprecating humor, and jokes and puns with explicit vocabulary or terms broadly perceived as politically
incorrect or unacceptable in a professional setting.
Triggers of toxicity
Failed Use of Tool/Code or Error Message
Some comments actually report the problem in some detail to help the project or receive help with their immediate problem, but still include toxicity, typically expressing frustration.
For example, as one such user of a popular library puts it, “I just tried reinstalling your buggy, sh**ty software for the third time. Maybe you guys can get one that works right and stick to it without changing it all the
time” .
Yet, in other cases, users simply vent about problems
without seeking help or any attempt to provide constructive feed-
back to the project.
In some cases, the users respond with toxic messages when asked for more information or asked to follow the issue template,
for example “Yeah, not really sorry i’m lazy, and it’s more to help you then me. It’s simple to understand: […]. don’t need a ret**ded format to understand that! thanks”
Toxicity triggered by failed tool use is often entitled, insulting, unprofessional, or just trolling e.g., “It doesn’t work. F*** this”
Politics/Ideology
We fairly frequently observed toxicity arising over politics or ideology differences, e.g., referring to specific beliefs about open source culture, processes, or the involvement of specific companies (especially Microsoft was
a frequent target in our sample)
For example, a user wrote a hostile issue in a Microsoft project titled “WHY  ” which simply said “Revenue. F**k you guys”
” which simply said “Revenue. F**k you guys”
Past Interactions
Finally, we observed several cases where toxic comments were posted that referred to past interactions of the author with the project, without continuing to
discuss the previous technical issue, but shifting to personal attacks, complaints, or meta discussions about process.
For example, a user was unsatisfied with the response time on an existing issue so they created a new one asking “did you miss my comment or what?” These comments were often posted in a new issue after the old one was not answered or closed, and they often occur in the opening comment of the new issue
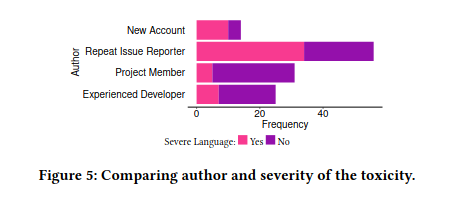
Authors of toxicity
-
New Account
- No or minimal prior activity
- Created just to use a particular software
- Usually engage in anonymous trolling
a new user was trying to download an application but was having issues and wrote an issue titled “Cant even install the fu**ing app” in which they complained that they could not find the download, upon which another user pointed them to the project’s release page
-
Repeat Issue Reporter
- Have posted multiple issues but have no contributions.
A six-year old account with a clear name, profile picture, and contact email has created hundreds of issues over the years, before posting an issue “sh**ty package” (with no context or further content) to a mid-sized repository of a web UI component.
-
Experiences contributors
- Tend to use less sever language
- But participate in all kinds of toxicity
An experienced contributor was upset that a new update did not include Python 2, a project member responded with a workaround, to which the author then responded “and I recommend you quit! There are many more where python2 is used […] and you deleted it from the repository. Do you think at all with your head or do you have a hamburger head place?”
-
Project member
- Toxicity occurs in smaller projects in reaction to a demand, complaint,
or perceived affront from another user (which are not toxic)
- Tend to be less severe. Mostly unprofessional or insults targeted at code.
- Tend to not engage in unprovoked attacks.
you can be mad all you want, but let’s be realistic here… this project you’re fighting for so passionately, doesn’t have as many stars as I have thumbs down for telling you that you’re being ridiculous”
Project Characteristics
Project size
- Vast majority of toxic comments were written in popular repositories with high levels of activity.
- In less popular projects, the nature of toxicity is often insulting, trolling, or unprofessional, mostly directly in the opening comment, but we found no entitled comments, possibly because users have lower expectations in the first place
Several toxic comments in small projects appeared to be trolling or jokes among friends, e.g., “Dear Mr. [project owner name], Could you perhaps please get your s**t together and reincorporate the brilliant switch statement once again, bitch. XoXo, [author]”
Project domain
- Toxicity occurred often in projects we consider as libraries or end-user-focused applications, which likely also are the most common kinds of projects on GitHub.
- toxicity in projects related to gaming and to mobile apps tends to use more severe language, e.g., more cursing,
After toxicity: harms and reactions
Tools to curb discussions
- Closing/Locking/Deleting issues
- Deleting/Editing/Hiding comments
- Blocking users
- Invoking the code of conduct
Reactions
When maintainers invoked the code of conduct, the author of the toxic comment usually did not engage any further. However, there were also a few cases where the author pushed back on being policed in their speech
"Again. No discussion allowed. No critique allowed. Just pushing fingers into the ears and singing. To avoid hearing about the impending doom, to avoid hearing the truth about the quality of this project”
In one case, a user called out for violating the code of conduct responded insisting “I will neither change my language, nor my tone or style. Both, language and tone, are perfectly valid, given the circumstances. I will remain myself, and will repel this attack to my individuality”
referring to invoking the code of conduct as “CoC-Fascism,” upon which projects members banned the user.
Discussion and Implications
- Toxicity presents differently on GitHub (compared to other platforms)
- Open-source experience does not prevent toxicity.
- Research into harms of toxicity is needed. We can’t reliably measure harms
that toxic comments cause, especially indirect harms on bystanders and potential future contributors who decide not to engage with the repository or open source in general.
- In almost all cases, a maintainer reacts to the toxic issue or comment, even if just to close or lock the issue. That is, maintainers need to use some of their time for extra work.
- Maintainers often engage to explore whether there is truly an issue behind
strongly worded complaints. Even when maintainers invoke the code of conduct, they usually do so in a custom comment tailored to the specific case. All this requires substantial effort which can be emotionally taxing to developers over time and cause fatigue.
- There are opportunities to build open-source specific toxicity detectors. Early interventions are promising.