Open source tools for Indigenous and low-resourced language archiving
Hi all, I want to share a problem statement and invite those of you interested to join us build tools for documenting Indigenous/tribal and other low-resourced languages.
Based on interaction with local communities, the OpenSpeaks Archives has made a list of tools essential for documenting oral history in audio and video in languages that often lack scripts. These tools will help communities in India and globally in documenting, subtitling, and archiving recordings. We work with language archivists, community documenters, and Wikimedians. Our recordings are used by communities for language learning and advocacy, and we upload them to Wikimedia projects (Wikipedia, Wikimedia Commons, Wikisource). We’ll release all tools in MIT/GPL.
We need your help to build, complete, or stress-test four key tools:
a. OpenSpeaks Subtitler: offline, multilingual subtitling and uploading subtitles to Wikimedia Commons
b. Media Metadata Viewer & Compress Helper: Quickly inspect media properties and compress files for sharing/editing
c. Media Duration Calculator: Batch calculate total media duration of audio and video files inside folders for project planning/budgeting
d. Multimedia Organization Tool: Organise, categorise, tag, and batch-rename multimedia files (video, audio, image) inside a folder using structured naming conventions for production workflows
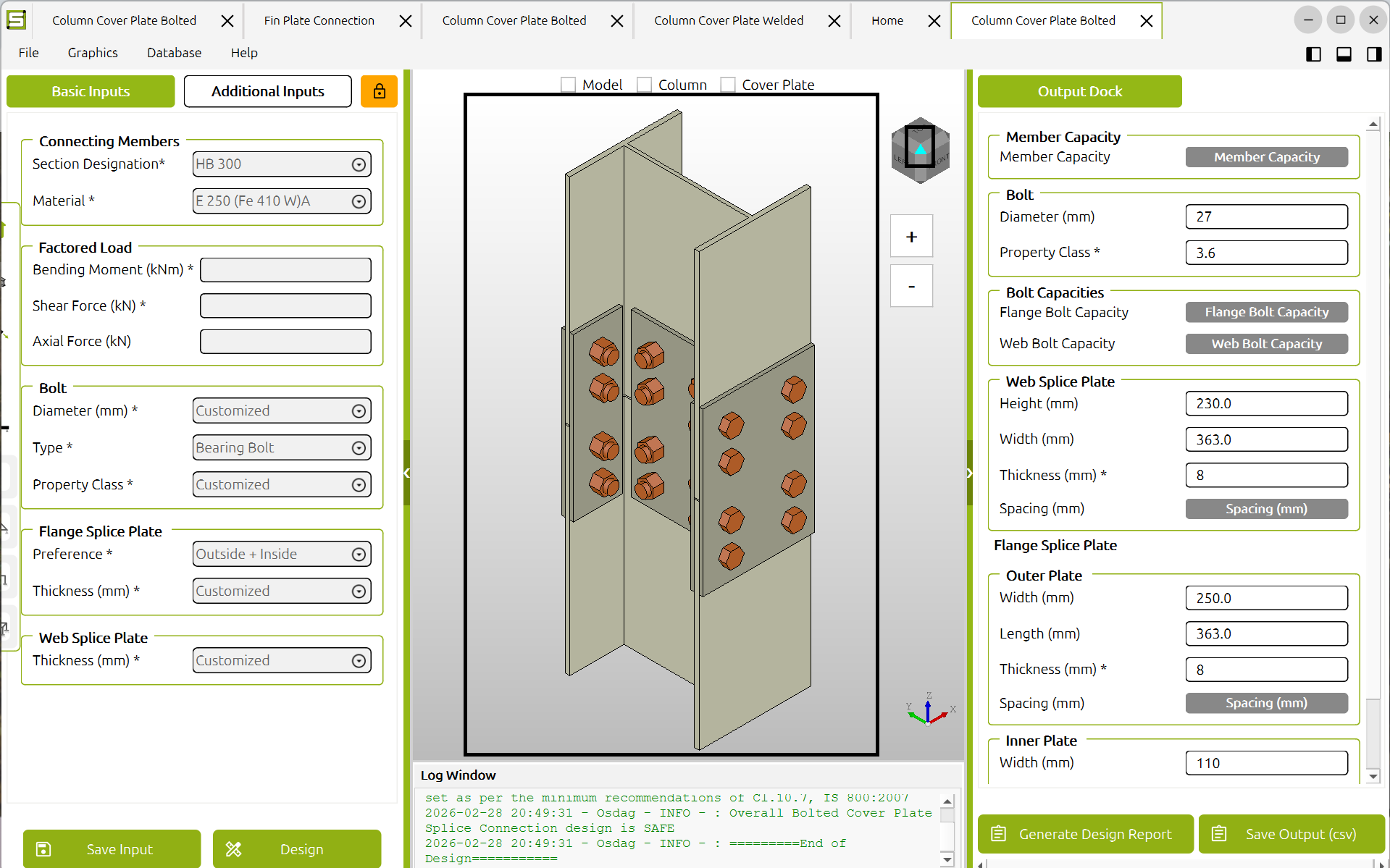
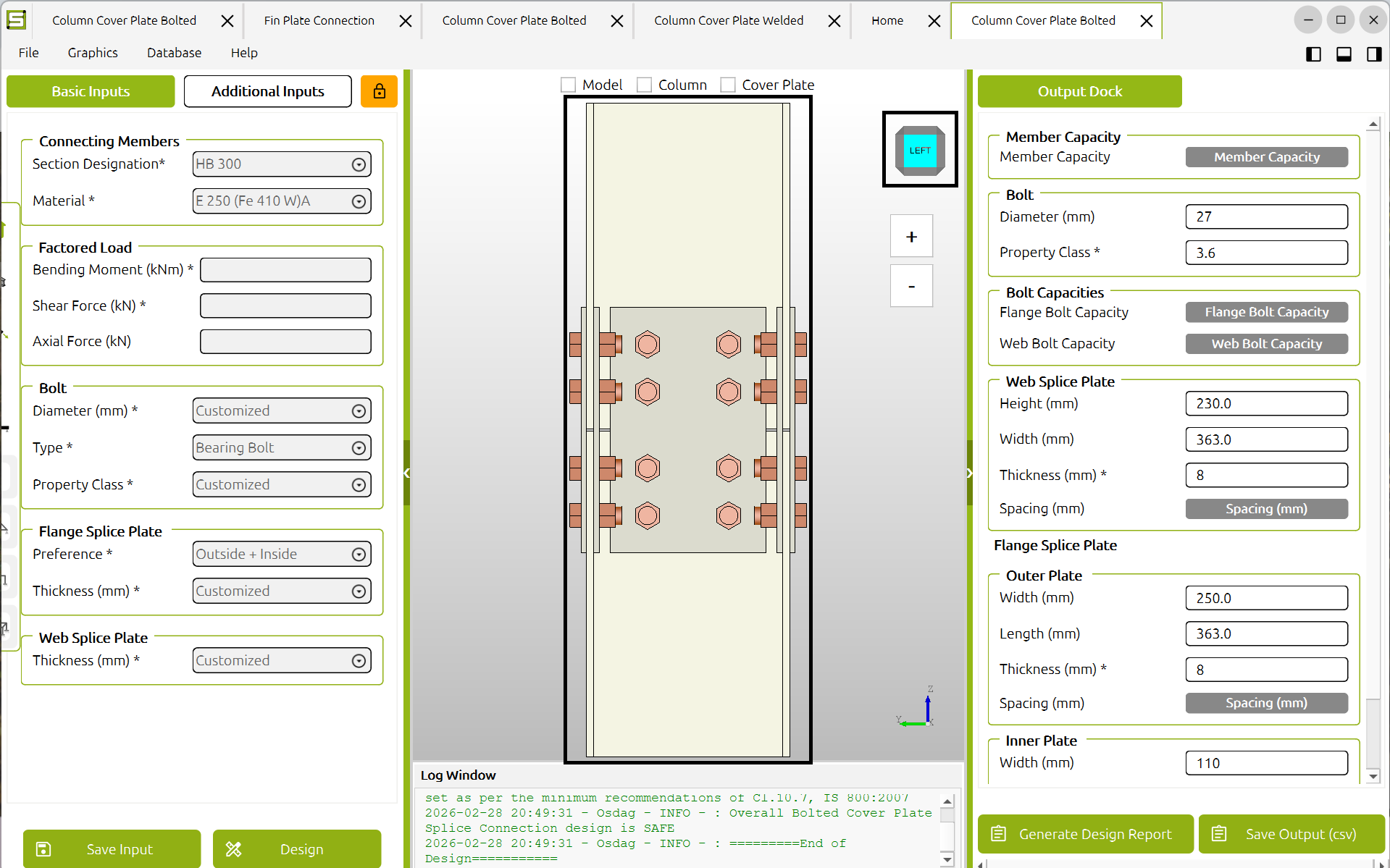
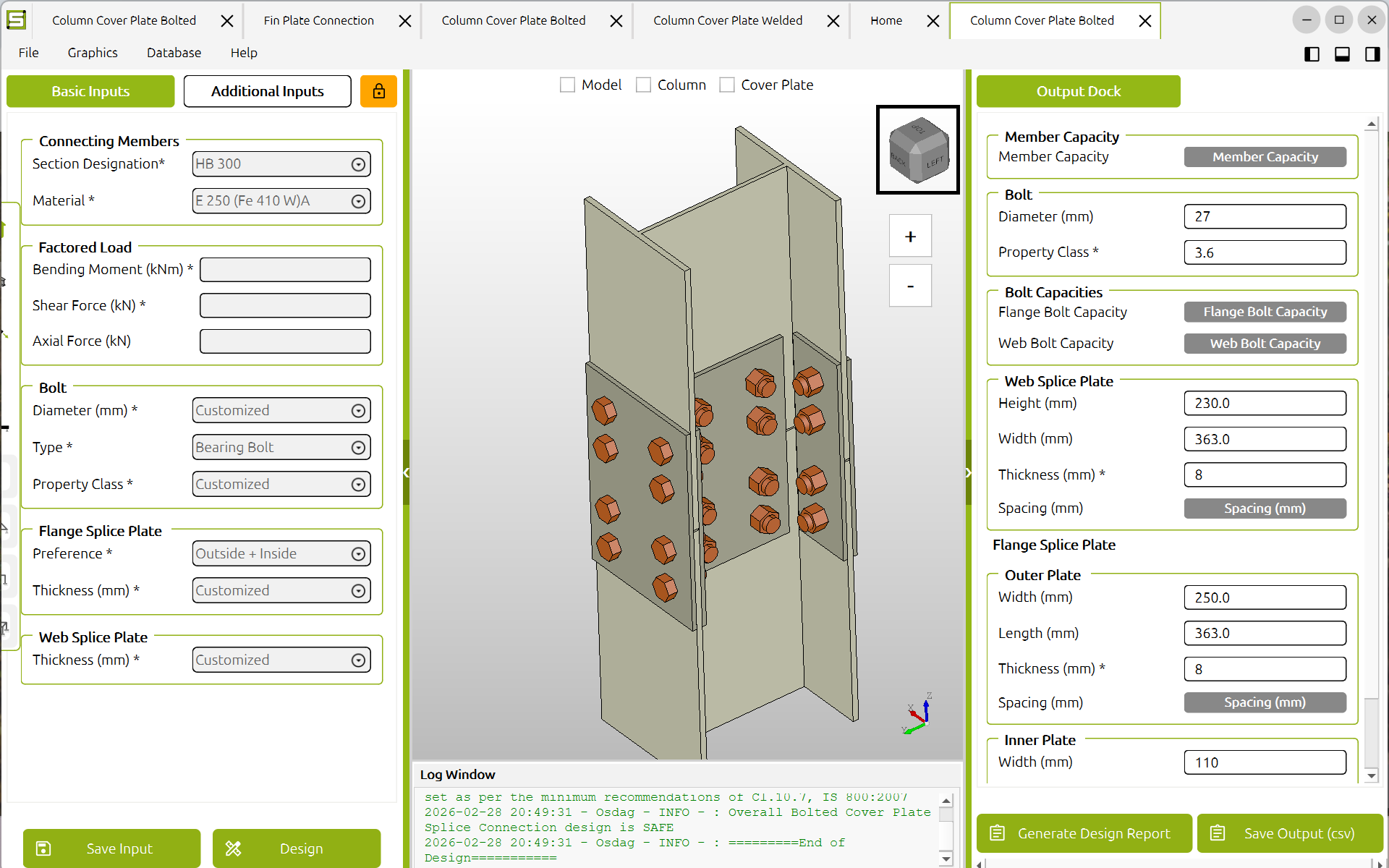
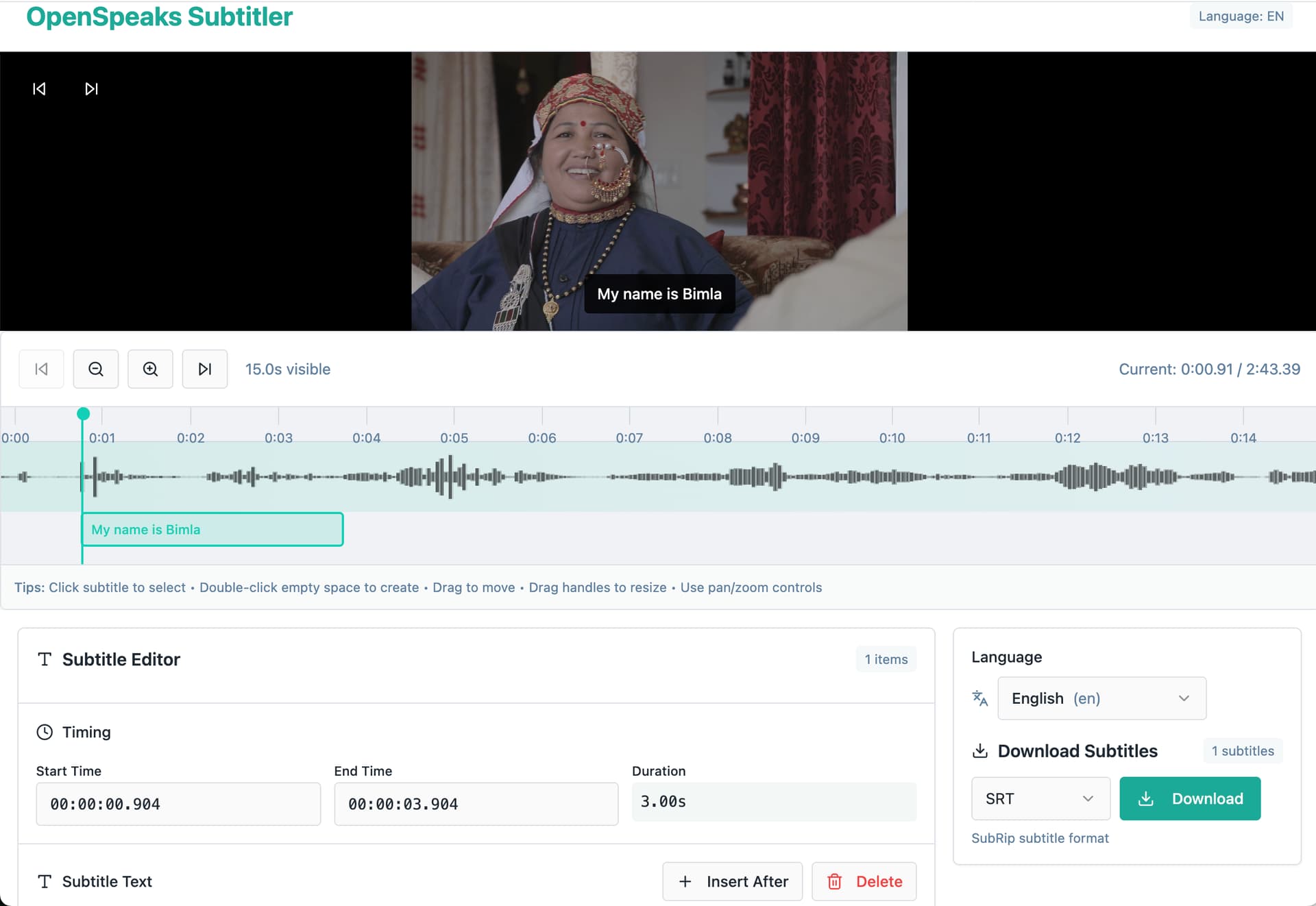
1. OpenSpeaks Subtitler (in active development — help us test and complete it)
A browser-based subtitle editor built specifically for oral history and language documentation recordings, with direct upload to Wikimedia Commons. A working prototype exists and a developer is currently building it, but we want more hands on testing and edge-case handling — especially for multilingual recordings and non-Latin scripts.
- Load local audio/video (MP4, MOV, WAV, MP3, etc.) — fully offline (offline version lacks Wikimedia Commons uploading option) via HTML5 player
- Auto-generate draft subtitle segments using silence detection
- Language selection from ISO 639 dropdown
- Export as SRT or VTT in UTF-8
- OAuth login and upload to Wikimedia Commons via the MediaWiki API
2. Media Metadata Viewer & Compress Helper (working prototype exists — needs a proper build)
Archivists often need to inspect and compress media files before uploading to Wikimedia Commons, which has strict file size limits. This tool combines both needs in one place. A prototype exists and is usable, but it needs a cleaner implementation.
- Load a media file and display: duration, resolution, frame rate, audio sample rate, bitrate, codec
- User inputs a target file size; tool calculates the required bitrate for re-encoding
- Export the compressed file
- Tech: HTML5/JS frontend; ffmpeg.wasm or native ffmpeg in an Electron wrapper
3. Media Duration Calculator (working prototype exists — needs a proper build)
A batch tool that scans a folder and calculates total media duration — useful for budgeting subtitling and translation work. Archivists regularly need to know: “how many hours of recordings do we have in this language cluster?” A prototype exists.
- Point to a local folder in computer; scan all audio and video files
- Output: total duration, audio-only total, video-only total
- Export results as plain text
- Tech: Node.js or Python + ffprobe; simple HTML/JS frontend
4. Multimedia Organisation Tool (working prototype exists — needs a proper build)
Fieldwork produces hundreds of files with inconsistent naming. This tool lets archivists categorise, tag, preview, and batch-rename files using a structured naming convention before upload. A prototype exists.
- Browse a local folder; list all video, audio, and image files
- Assign categories (A-roll, B-roll, etc.) and tags; add per-file notes
- Built-in media preview player
- Generate new filenames from a configurable pattern:
{language}-{type}-{names}-{subject}_{sequence}.{ext}
- Batch rename files in the filesystem; export an organisation log as CSV
- Tech: single self-contained HTML file (vanilla JS, File System Access API) — or React/TypeScript with Vite + Tailwind
All four tools are documented in detail (including wireframes and prototypes) at meta.wikimedia.org/wiki/OpenSpeaks/Tools.
If you are interested in contributing — whether for FOSSHack or independently — please reach out here or on our Meta talk page. We are happy to answer questions, provide test recordings and share any further details.
Why this matters:
Most subtitling, archiving, and media management tools are built for well-supported languages with scripts. An archivist documenting oral history in audio/video has no dedicated tooling for various features we’ve listed. They are forced to use general-purpose video editors. Our tools are small, focused, and designed for exactly that gap.